

Ollama保姆级教程:从零开始本地部署DeepSeek、Llama大模型(Windows/Mac/Linux通用)
想在自己电脑上跑大模型,却被复杂的Python环境、CUDA配置劝退?Ollama一个命令就能让DeepSeek、Llama、Qwen在你本地跑起来,无需联网,完全免费。
一、Ollama是什么
Ollama是一个开源跨平台的大模型本地运行工具,支持macOS、Windows、Linux。它的核心价值在于一个命令就能下载并运行大模型,自动处理量化、推理、API服务。目前已支持Llama 3、DeepSeek-R1、Qwen 2.5、Gemma等数百个主流模型。
二、安装Ollama(三平台通用)
macOS
访问 ollama.com 下载dmg安装包,拖入Applications即可。系统要求macOS Sonoma (v14)及以上,支持Apple M系列和x86架构。
Windows
官网下载OllamaSetup.exe,一路下一步。安装后Ollama后台自动运行,cmd或PowerShell直接执行ollama命令。NVIDIA显卡需驱动版本452.39以上。
Linux
curl -fsSL https://ollama.com/install.sh | sh
安装完成后执行 ollama --version 验证是否成功。
三、运行你的第一个大模型
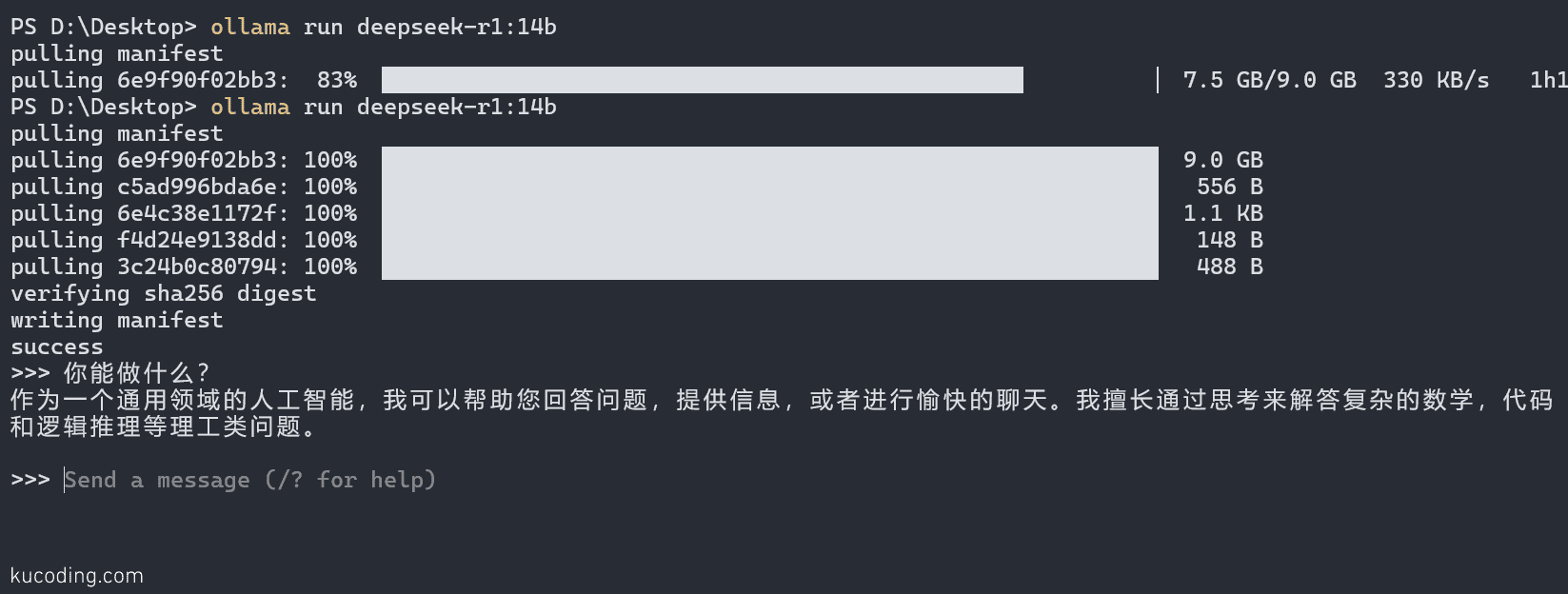
1. 下载并运行DeepSeek-R1
# 下载7B参数版本(推荐,显存8GB即可) ollama run deepseek-r1:7b # 或使用轻量版1.5B(4GB内存可跑) ollama run deepseek-r1:1.5b
首次运行会自动下载模型文件,之后直接启动对话。
2. 常用命令速查
ollama list # 查看已下载的模型 ollama pull llama3.2 # 下载指定模型 ollama rm deepseek-r1 # 删除模型 ollama serve # 启动API服务(端口11434) ollama ps # 查看运行中的模型
四、模型管理与选择
Ollama官方模型库(ollama.com/library)提供数百个模型。推荐新手从这几个开始:
| 模型 | 参数量 | 适用场景 | 最低配置 |
|---|---|---|---|
| DeepSeek-R1:1.5b | 1.5B | 轻量对话、代码补全 | 4GB内存 / 无GPU |
| Llama 3.2:3b | 3B | 通用对话、文本摘要 | 6GB内存 / 4GB VRAM |
| Qwen 2.5:7b | 7B | 中文优化、长文本 | 8GB内存 / 6GB VRAM |
| DeepSeek-R1:14b | 14B | 复杂推理、代码生成 | 16GB内存 / 12GB VRAM |
五、API调用与生态集成
Ollama支持OpenAI兼容API,可与ChatBox、AnythingLLM、LangChain等工具集成:
# 启动API服务
ollama serve
# 测试API
curl http://localhost:11434/api/generate -d '{
"model": "deepseek-r1:7b",
"prompt": "用中文解释什么是大模型"
}'
还可接入VS Code插件Continue、Obsidian插件等,在写作和编程中直接调用本地模型。
六、常见问题
Q: 下载速度太慢怎么办?
设置镜像加速:export OLLAMA_HOST=0.0.0.0,或使用ModelScope国内镜像源下载模型文件后手动导入。
Q: 显存不够能跑吗?
可以,Ollama支持纯CPU推理。选择1.5B或3B的小模型,即使无独显也能流畅对话。
Q: 中文回答效果不好?
优先选择DeepSeek-R1或Qwen系列,它们是中文优化最好的开源模型。在提示词中明确要求「请用中文回答」也能改善效果。
Q: 如何自定义模型参数?
创建Modelfile指定temperature、system prompt等:ollama create my-model -f ./Modelfile。
七、总结
Ollama是目前最简单的大模型本地部署方案,一条命令就能跑起DeepSeek、Llama等主流模型。无需Python环境,不用配CUDA,macOS/Windows/Linux全平台通用。配合API服务和生态工具,可以实现从个人助理到编程助手的完整链路。
如果你还在为在线AI的隐私和费用发愁,Ollama值得一试。4GB内存的笔记本也能跑,完全免费,永久离线。



